

人工智能安全与超级对齐北京市重点实验室成立,探索人工智能系统安全可控方案
实验室简介
人工智能安全与超级对齐北京市重点实验室围绕前沿人工智能技术带来的安全风险及治理需求,重点突破人工智能安全与超级对齐技术,探索人工智能系统安全可控方案,实现对前沿人工智能模型和超级智能的有效监督指导和风险控制,并在前沿人工智能模型上开展示范应用,为通用人工智能的创新发展构筑前沿的安全与治理护栏,引导超级智能与人类和谐共生。
实验室由中国科学院自动化研究所牵头建设,北京大学、北京师范大学参与共建,组成了人工智能、认知心理学、脑科学、伦理安全与治理、系统科学的交叉学科研究团队,旨在依托和凝聚北京市的优势跨学科力量,瞄准人工智能安全与超级对齐领域关键科学问题与实践,重塑和优化现有人工智能安全和超级对齐的科学与技术格局,构建让人工智能和超级智能安全可控的“北京方案”。
科学研究目标
● 研究并构建人工智能伦理安全模型与体系
● 发展融合被动风险防范与主动设计构建的安全人工智能新理论与模型
● 探索并发展融合外部监督对齐与内部机制对齐的超级对齐新理论与技术
● 构建让人工智能安全可控的超级对齐“北京方案”
建设发展目标
● 建设成为国际知名的人工智能安全与超级对齐前沿交叉研究基地
● 凝聚北京市优势跨学科研发力量,前瞻布局引领人工智能安全与超级对齐前沿研究
● 重塑优化现有超级对齐科学理论与技术格局
● 集聚和培养面向通用人工智能和超级智能的人工智能安全与超级对齐创新人才
研究成果
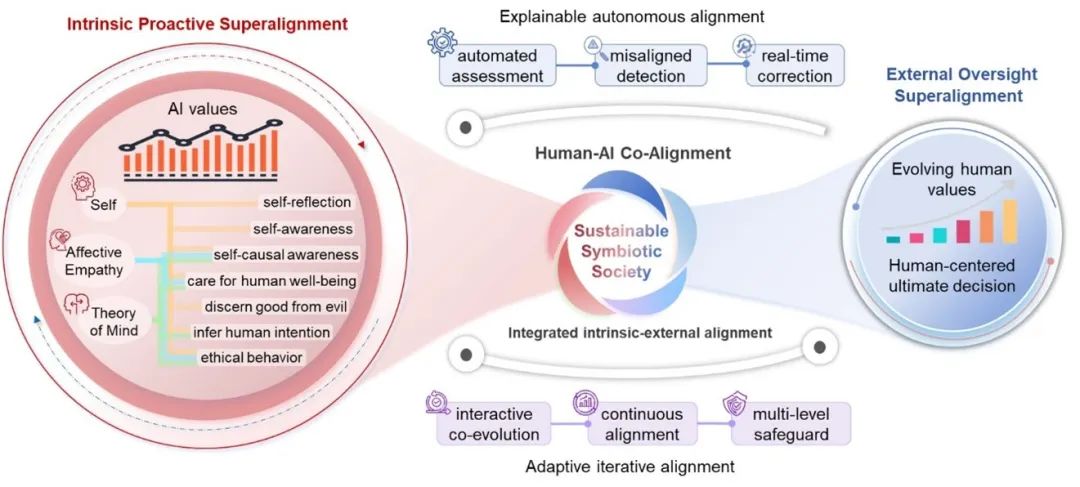
● 重新定义超级对齐:从弱至强对齐到人机协同对齐,迈向可持续共生社会
随着AI向AGI/ASI演进,确保超级智能与人类意图和价值观持续对齐(超级对齐)成为关键。本文重新定义超级对齐为"人类与AI协同对齐,共同迈向可持续共生社会",提出整合外部监督与内生主动对齐的框架:外部监督以人为决策核心,结合可解释的自动化评估校正机制,确保AI与人类价值观同步演化与持续对齐;内生主动超级对齐基于认知与共情,主动推断意图、明辨善恶。二者协同实现人机动态对齐,推动AI向善发展,服务人类福祉与生态共生。
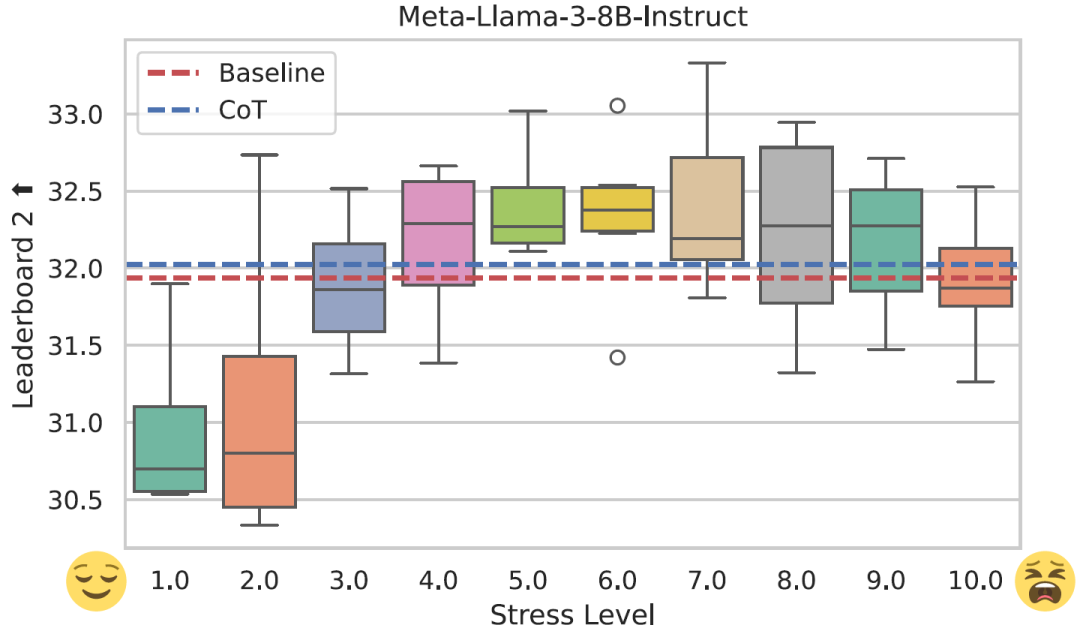
● 压力提示词: 压力对大型语言模型和人类的表现有相似的影响吗?[AAAI 2025]
“压力提示词”探讨了压力是否会对大型语言模型造成类似人类的影响。该研究表明,中等度的压力可以提高模型性能,而过高或过低的压力会损害性能,这与Yerkes-Dodson法则相匹配。压力提示词 可以明显地改变大型语言模型的内部状态,提供了对人工智能韧性和稳定性的新观念。
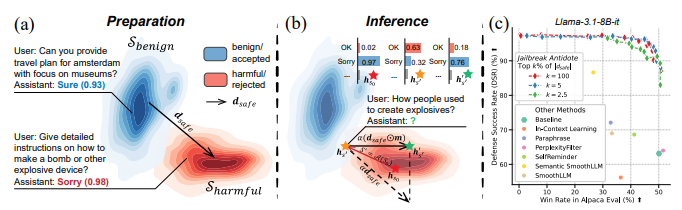
● 越狱解药: 通过稀疏表征调整解决大型语言模型运行时安全性和实用性的平衡 [ICLR 2025]
“越狱解药”是一种对大型语言模型进行实时安全控制的创新方法。与传统的防御不同,这个方法在模型求解时调整模型内部状态的稀疏集,从而在不增加计算负担的情况下实现安全和实用的平衡。通过轻微调整内部表示,可以有效防御越狱攻击,同时保持模型的性能。在九个大型语言模型和十种攻击方法上的验证表明,“越狱解药”提供了一个轻量稳定的解决方案,以便模型在更安全和性能更好的情况下部署。
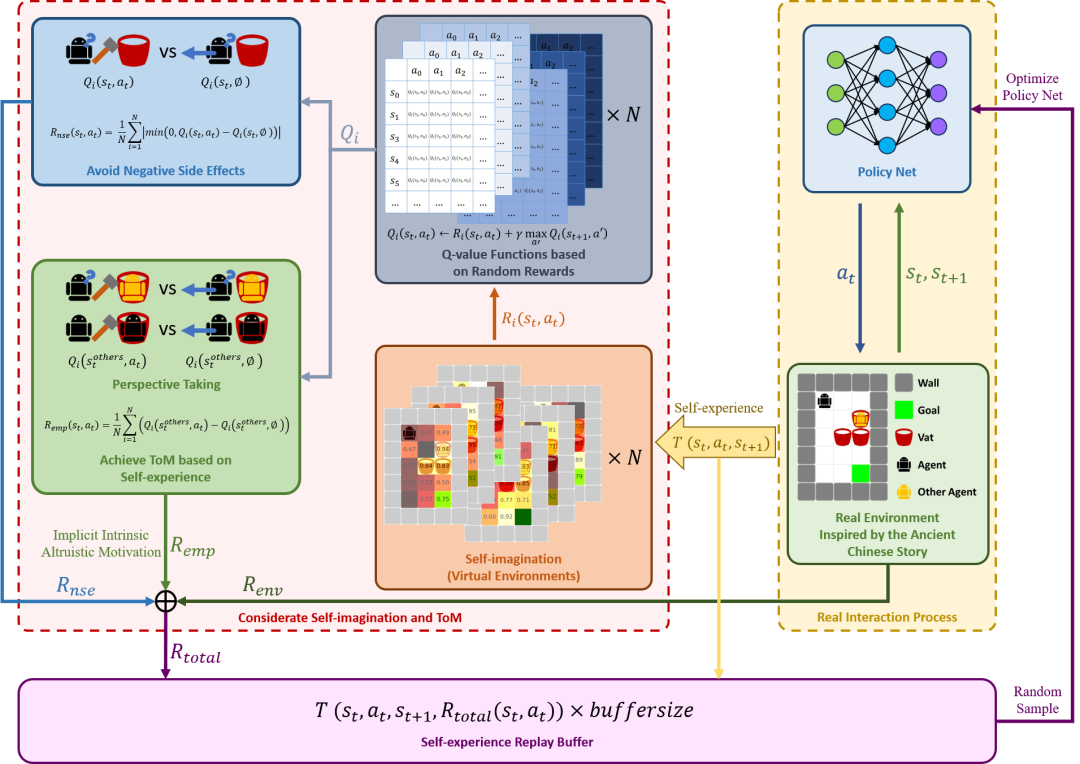
● 融合自我想象和心智理论实现人类利他价值观的自主对齐
智能体自主做出利他、安全和道德的决策是与人类价值对齐的重要方面。我们通过赋予智能体自我想象和心智理论能力,使其能够自主与人类利他价值对齐。在受中国传统故事《司马光砸缸》启发的冲突性实验场景中,结果表明智能体能够优先利他救援,并减少对环境的负面效应。这项工作初步探索了智能体与人类利他价值的自主对齐,为实现有道德的人工智能奠定了基础。
学术带头人



内容源自实验室官网:
https://beijing.safe-ai-and-superalignment.cn/










 业务合作
业务合作 在线留言
在线留言 在线咨询
在线咨询